In March 2025, someone cloned a Go library called atlas-provider-gorm, faked thousands of stars from freshly-created accounts, and slipped a remote shell payload into the init path. The star count looked like traction. It was bait.
Carnegie Mellon’s StarScout study (ICSE ‘26) counted 4.5 million suspected fake stars on GitHub from 1.32 million accounts. $5 buys 100 stars with paced delivery and “star insurance” in case GitHub’s cleanup catches them. Crypto projects run the highest fraud rates (unionlabs 47% fake, shardeum 42%). AI repos sit lower per project but higher in aggregate.
Why Stars Broke
One benchmark, one $10B company
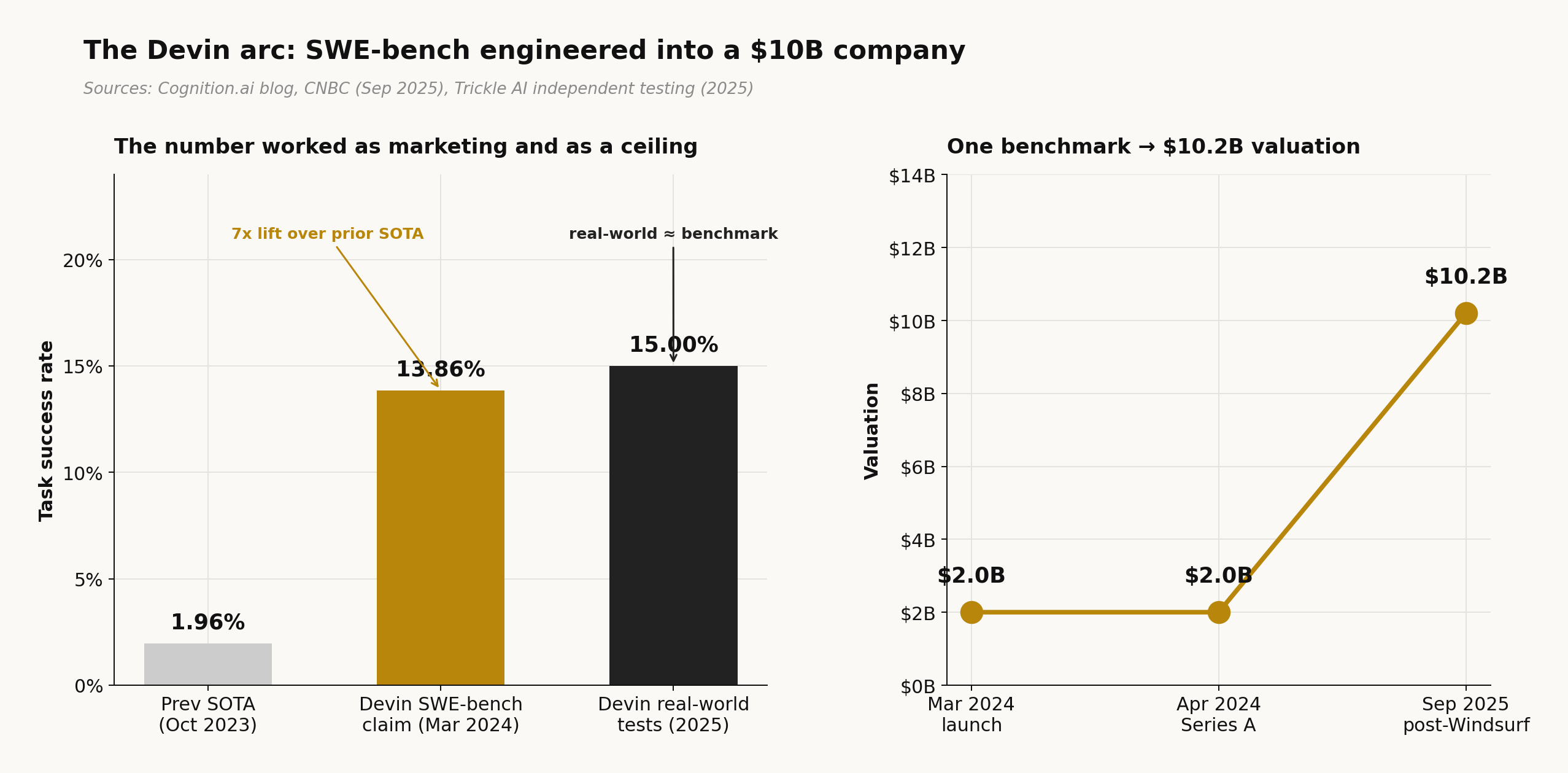
John Yang released swe-bench from Princeton in October 2023. It sat mostly ignored for five months. Two weeks before Cognition launched Devin in March 2024, Walden Yan emailed Yang: “we have a good number.”
The number was 13.86%, against a prior best of 1.96%. Cognition hit $10.2 billion in valuation by September 2025 (CNBC). Independent testing (Trickle AI, 2025) later put Devin’s real-world success rate at 15%, matching the benchmark almost exactly. The score served as the marketing pitch and as the performance ceiling.
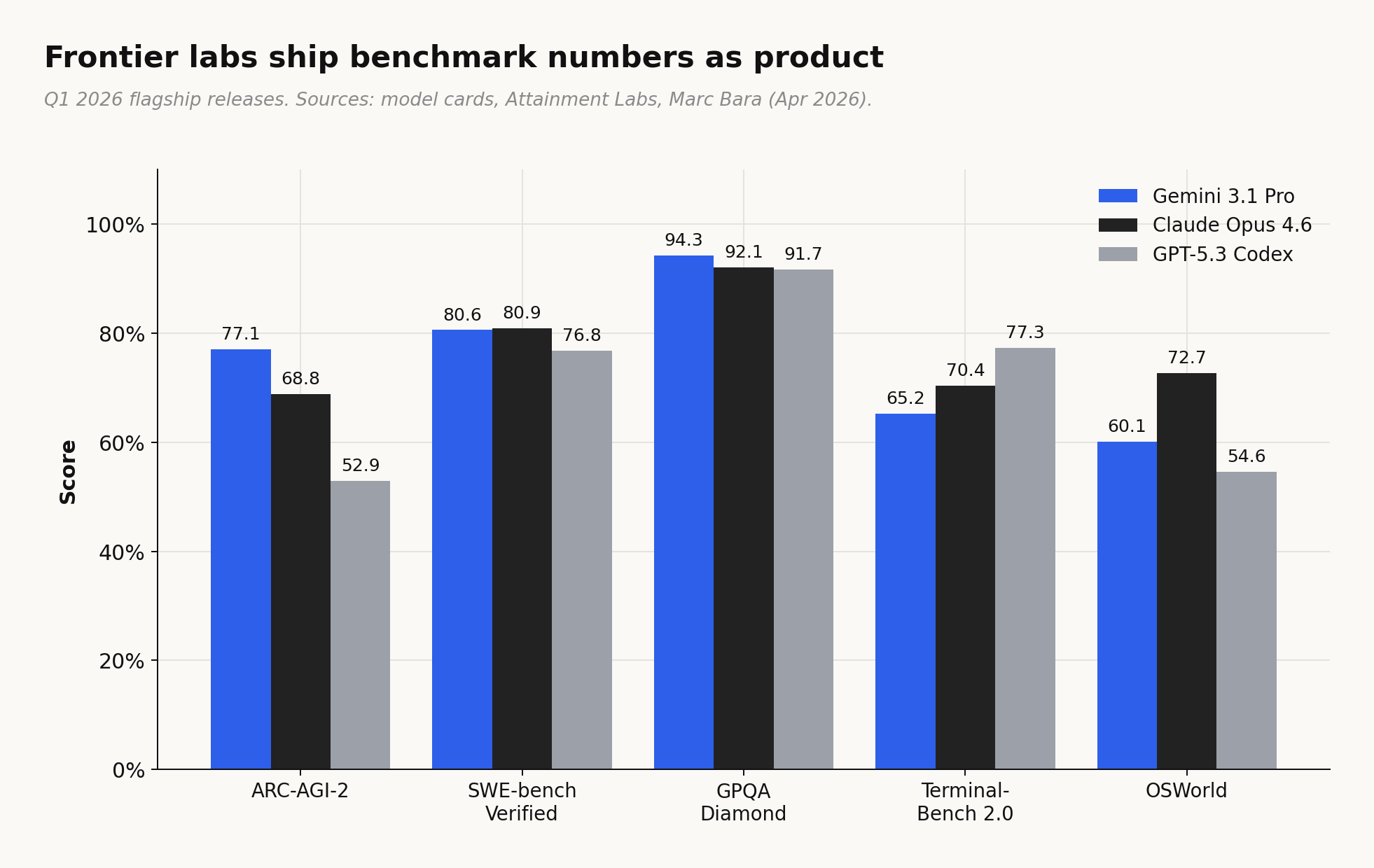
Every frontier model shipped in Q1 2026 led with benchmark scores. Not stars, not downloads. Gemini 3.1 Pro, Claude Opus 4.6, GPT-5.3 Codex all opened their announcements with numbers on SWE-bench, ARC-AGI-2, GPQA Diamond, Terminal-Bench. The press releases read like leaderboard entries.
Public benchmarks don’t reveal the truth
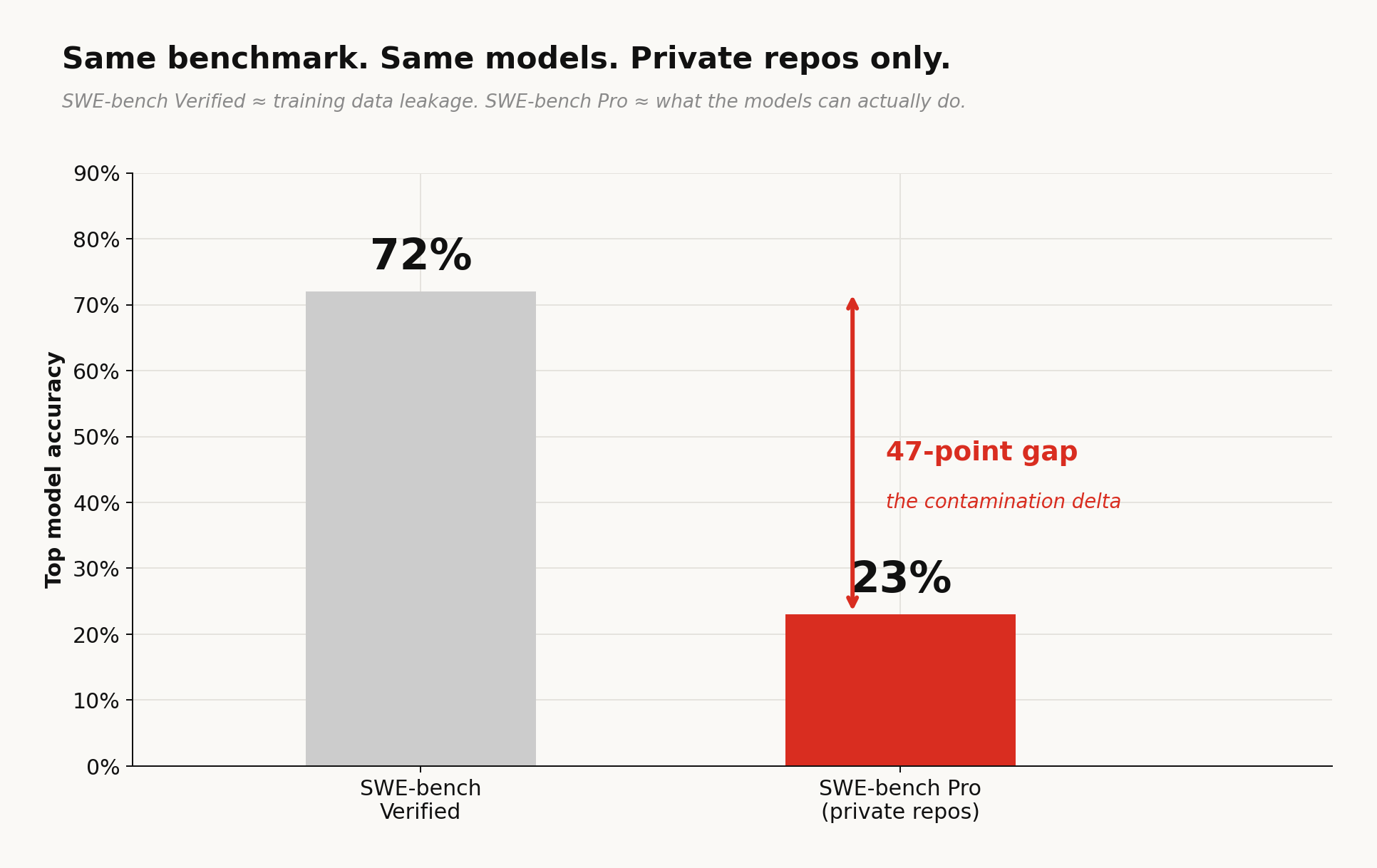
SWE-bench Verified, the most-cited coding eval, puts top models above 70%. Restrict the test set to private repositories that couldn’t have appeared in training data and scores drop to 23% (SWE-bench Pro). That 47-point gap is the contamination-delta — the distance between what models memorized and what they can actually do.
arc-agi-3 (released March 24 2026) took a different approach entirely. Where ARC-AGI-2 used static grid puzzles, ARC-AGI-3 drops the model into interactive turn-based environments — small games where the agent is never told the rules, never told the objective, and has to figure out what “winning” means through exploration. Scoring uses rhae, where the human-to-model efficiency ratio is squared before averaging; a model 10x slower than a human scores 1%, not 10%. Gemini 3.1 Pro, the same model that hit 77.1% on ARC-AGI-2, scores 0.37% on ARC-AGI-3. The test changed from “can you solve this puzzle” to “can you learn a new environment from scratch.”
Why benchmarks persist anyway ?
Papers calling benchmarks broken are now a genre of their own. Nature ran “Is your AI benchmark lying to you?” in August 2025. An Oxford Internet Institute study found only 16% of 445 LLM benchmarks use rigorous scientific methods; half claim to measure “reasoning” without defining the term. The Register titled their coverage “AI benchmarks are a bad joke, and LLM makers are the ones laughing.” Labs know all of this. They lead with benchmark scores anyway.
The Structural Trap
Ilya Sutskever put the contradiction plainly in December 2025: “How to reconcile the fact that they are doing so well on evals… But the economic impact seems to be dramatically behind.” GPT-5.2 Thinking scored 70% on GDPval, outperforming industry professionals across 44 occupations. Real-world automation impact: still lagging. The evals work as marketing. Whether they work as measurement is a separate question the industry has stopped asking.
The cost of faking it
Stars cost one click. Public benchmarks cost a training run - motivated labs can teach the tests. But long-horizon agentic work is in a live environment resistant to pre-training.
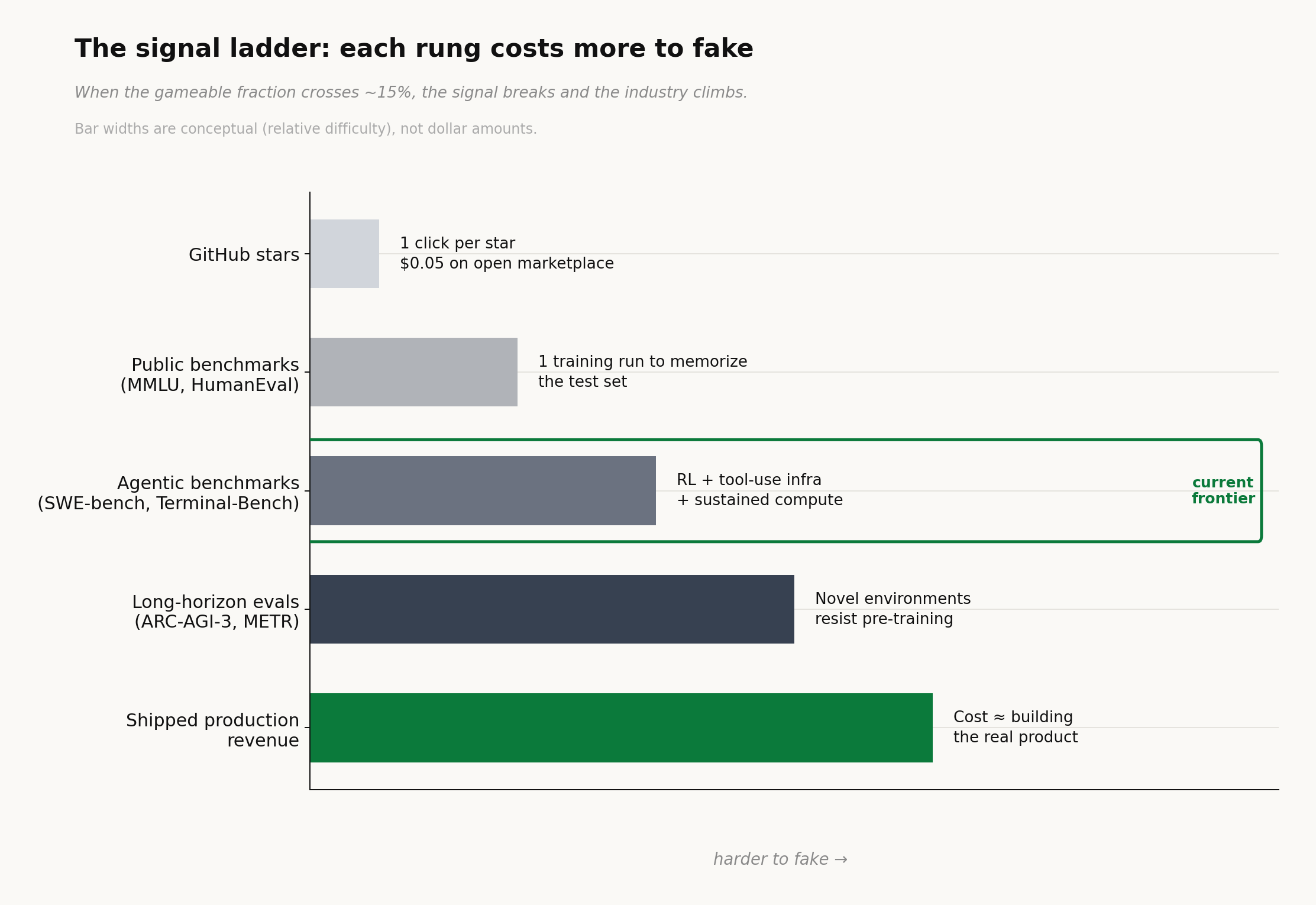
METR measured the trend directly: the length of task a model can complete at 50% reliability has been doubling every seven months for seven years (arXiv:2503.14499). A model that reliably handles 12-hour autonomous tasks occupies a different economic category than one that aces a multiple-choice exam.
ARC Prize Foundation reported that by late 2025, labs were gaming benchmarks through brute-force data saturation. Bessemer’s State of AI 2025 predicts public evals will follow the same path as stars: useful, commoditized, gamed, abandoned. MIT Technology Review ran “AI benchmarks are broken” in March 2026. All accurate.
Independent benchmarks are fighting back. METR, ARC-AGI, and VendBench keep raising the verification bar; each new eval is harder to saturate than the last. But the market is already moving past benchmarks toward verified outputs. Look at how the top agents position themselves in Q1 2026: Claude Code leads with 80.9% SWE-bench, then immediately cites $2.5B ARR (SemiAnalysis). Codex CLI leads with 77.3% Terminal-Bench, then cites one million developers in its first month. Cursor skips benchmarks entirely and leads with 360K paying customers and a $29.3B valuation. Devin cites a 67% PR merge rate on defined tasks. The signal is migrating from “what score did you get” to “what did you ship and who paid for it.”
The Economics of Credibility
OpenAI and Microsoft quietly settled on their own unfakeable benchmark: $100 billion in profits (The Register, Nov 2025). Their internal AGI trigger is a revenue number, not an eval score. Measuring money turned out to be easier than measuring intelligence.
Stars measured who clicked, Benchmarks measure what the model can do on a test. Verified outputs will measure what really shipped. Each signal costlier, harder to fake.